Nâng trình phân tích dữ liệu kinh doanh bằng những khóa học của MDA

Knowledge
30/09/2023
Data Pipeline là gì? Tất tần tật những điều cần biết về Data Pipeline
Mục Lục
Dữ liệu chính là chìa khóa giúp bạn có cái nhìn tổng quan về hiệu quả của quy trình làm việc. Khi dữ liệu đến từ nhiều nguồn và tồn tại ở nhiều định dạng khác nhau, Data Pipeline là bước quan trọng để tổng hợp và phân tích dữ liệu một cách đáng tin cậy. Cùng MDA tìm hiểu về Data Pipeline là gì và những điều bạn nên biết về Data Pipeline trong bài viết dưới đây nhé!
Data Pipeline là gì?
Data Pipeline là một khái niệm trong lĩnh vực công nghệ thông tin, đề cập đến quá trình di chuyển, xử lý và chuyển đổi dữ liệu từ nguồn đến đích tự động và liên tục. Đây là một hệ thống quản lý luồng dữ liệu dùng để tổ chức, quản lý và thực hiện các quy trình xử lý dữ liệu trong môi trường có nhiều nguồn dữ liệu khác nhau.

Tìm hiểu Data Pipeline là gì?
Trong một Data Pipeline, dữ liệu được di chuyển qua các bước xử lý khác nhau để tiến hành chuẩn hóa, tích hợp với dữ liệu khác để tạo ra một bộ dữ liệu hoàn chỉnh. Quá trình này có thể bao gồm các hoạt động như trích xuất, biến đổi, tải dữ liệu (ETL), xử lý phân tán, chuyển đổi định dạng, kiểm duyệt và đồng bộ hóa dữ liệu.
Tầm quan trọng của Data Pipeline trong quản lý dữ liệu
Vậy vai trò của Data Pipeline là gì? Data Pipeline giúp tổ chức và quản lý dữ liệu một cách tự động, từ đó có thể loại bỏ sự can thiệp của con người để giảm thiểu nguy cơ sai sót. Hơn nữa, nó giúp tăng tính nhất quán và đáng tin cậy của dữ liệu, đảm bảo rằng dữ liệu luôn được cập nhật và sẵn sàng sử dụng.
Data Pipeline cũng tạo điều kiện cho việc tích hợp dữ liệu từ các nguồn khác nhau. Quá trình ETL (Extraction, Transformation, Loading) giúp trích xuất, biến đổi và tải dữ liệu từ nhiều nguồn, đồng nghĩa với việc dữ liệu có thể được tổ chức và kết hợp thành một bộ dữ liệu hoàn chỉnh. Điều này giúp cho người dùng sẽ có cái nhìn tổng quan và đưa ra được các quyết định đúng đắn.
Vai trò quan trọng của Data Pipeline trong quản lý dữ liệu
Một điểm đáng chú ý khác là Data Pipeline hỗ trợ xử lý dữ liệu thời gian thực (real-time). Bằng cách di chuyển và xử lý dữ liệu một cách nhanh chóng và liên tục, Data Pipeline cho phép cập nhật dữ liệu ngay lập tức và đưa ra phản hồi nhanh chóng. Điều này rất quan trọng đối với các ứng dụng như giao dịch tài chính, giám sát hệ thống, quảng cáo trực tuyến.
Data Pipeline cũng tạo điều kiện thuận lợi cho việc xử lý và phân tích dữ liệu lớn (Big Data Analytics). Với sự phát triển của dữ liệu đại chúng và công nghệ tính toán, việc xử lý dữ liệu lớn trở nên phức tạp hơn bao giờ hết. Data Pipeline tận dụng sức mạnh của hệ thống phân tán và tính toán đám mây, giúp nâng cao hiệu suất và tăng khả năng chịu tải của hệ thống.
Các loại Data Pipeline phổ biến
Có nhiều loại Data Pipeline phổ biến được sử dụng trong quản lý dữ liệu. Để tìm hiểu rõ hơn về Data Pipeline là gì thì dưới đây là một số loại Data Pipeline phổ biến:
- Batch Data Pipeline: Đây là loại Data Pipeline được sử dụng để xử lý dữ liệu theo cách đồng bộ và định kỳ. Dữ liệu được gom nhóm và xử lý trong các quá trình chạy hàng loạt.
- Real-time Data Pipeline: Loại này cho phép xử lý và chuyển đổi dữ liệu trong thời gian thực. Real-time Data Pipeline thích hợp cho các ứng dụng yêu cầu phản hồi nhanh chóng.
- Streaming Data Pipeline: Đây là loại Data Pipeline được sử dụng để xử lý dữ liệu đến liên tục và không ngừng. Dữ liệu được xử lý theo luồng và được gửi từ nguồn đến đích một cách liên tục.
- Cloud Data Pipeline: Loại Data Pipeline này được triển khai và vận hành trong môi trường đám mây. Cloud Data Pipeline sử dụng các dịch vụ và tài nguyên đám mây để xử lý và chuyển đổi dữ liệu.
- Hybrid Data Pipeline: Đây là sự kết hợp của nhiều loại Data Pipeline, kết nối các nguồn và đích dữ liệu trong một hệ thống phức tạp.
Một số loại Data Pipeline phổ biến
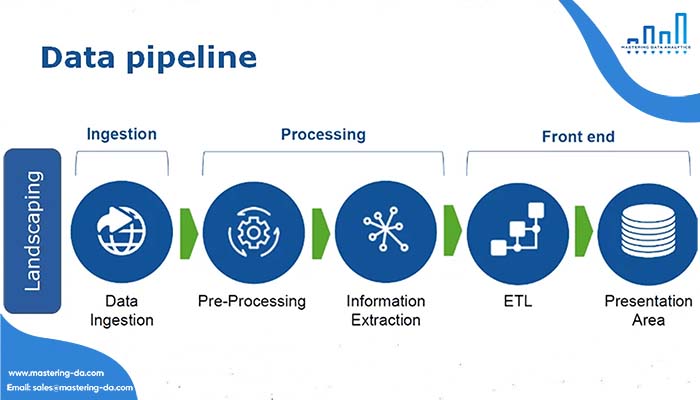
Data Pipeline Architecture
Data Pipeline Architecture bao gồm: Data Ingestion, Data Transformation, Data Storage.
Data Ingestion
Data Ingestion (tiếp thu dữ liệu) trong kiến trúc Data Pipeline là quá trình thu thập và chuyển dữ liệu từ nhiều nguồn khác nhau vào hệ thống Data Pipeline để tiếp tục xử lý. Data Ingestion là bước đầu tiên và cơ bản trong Data Pipeline Architecture. Quá trình Data Ingestion thường bao gồm các bước sau: thu thập dữ liệu, xác thực dữ liệu, chuyển đổi định dạng, lưu trữ dữ liệu, đồng bộ hóa dữ liệu.
Data Transformation
Data Transformation là quá trình chuyển đổi và xử lý dữ liệu từ định dạng ban đầu thành định dạng phù hợp với mục tiêu phân tích dữ liệu. Quá trình Data Transformation thường bao gồm các bước sau: Chọn lọc dữ liệu, chuẩn hóa dữ liệu, ghép dữ liệu, tính toán thông số và xử lý dữ liệu lỗi.
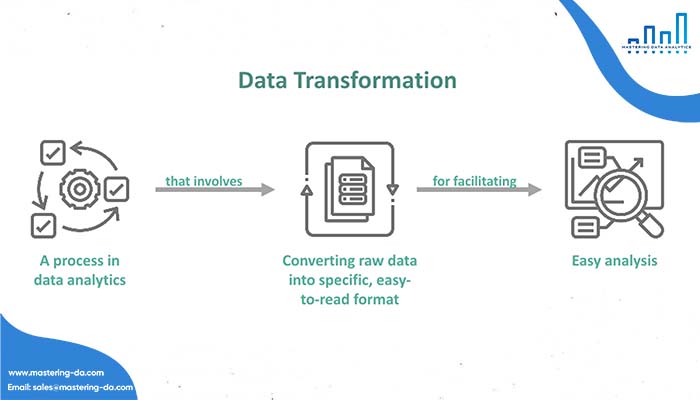
Quá trình Data Transformation
Data Storage
Data Storage là nơi lưu trữ dữ liệu trong quá trình xử lý thông qua Data Pipeline. Đây là một phần quan trọng của kiến trúc Data Pipeline, nơi dữ liệu được lưu trữ và sẵn sàng để tiếp tục xử lý và phân tích. Data Storage có thể được triển khai dưới nhiều dạng khác nhau như: Database, Data Warehouse, Data Lake, File Systems, Cloud Storage.
Ứng dụng của Data Pipeline là gì?
Hiện nay, hầu hết các doanh nghiệp đều đối mặt với một lượng dữ liệu cực kỳ lớn và có cấu trúc động. Thiết kế Data Pipeline có thể mở rộng và tái sử dụng giúp ích rất nhiều cho các doanh nghiệp cần sử dụng nhiều tài nguyên để phát triển các Data Pipeline. Vậy cụ thể các ứng dụng của Data Pipeline là gì?
Data Visualization
Data Pipeline đóng một vai trò quan trọng trong việc tạo ra Visualization từ dữ liệu. Bằng cách sử dụng Data Pipeline, dữ liệu có thể được chuẩn bị, xử lý và chuyển đổi để tạo ra các biểu đồ, đồ thị và bản đồ để hiển thị thông tin một cách hấp dẫn và dễ hiểu.

Data Pipeline đóng một vai trò quan trọng trong Trực quan hóa dữ liệu
Các ứng dụng của Data Visualization như sau:
- Tạo ra visualizations hấp dẫn: Visualization giúp tổ chức và truyền thông tin dữ liệu một cách rõ ràng. Từ đó giúp người dùng phân tích và đưa ra quyết định thông minh dựa trên dữ liệu.
- Trực quan hóa dữ liệu: Các biểu đồ và đồ thị giúp tạo ra hình ảnh rõ ràng và dễ hiểu về xu hướng, mối quan hệ và khía cạnh khác của dữ liệu.
- Hỗ trợ người dùng đưa ra quyết định đúng: Bằng cách tạo Visualization từ dữ liệu, người dùng có thể phát hiện ra những thông tin tiềm ẩn mà không thể nhìn thấy từ dữ liệu ban đầu.
- Truyền thông tin một cách rõ ràng và hấp dẫn: Người dùng có thể truyền tải thông tin một cách dễ dàng và thu hút sự quan tâm của đối tượng chú ý bằng cách sử dụng các biểu đồ và đồ thị
Exploratory Data Analysis
Exploratory Data Analysis (EDA) là quá trình khám phá và hiểu dữ liệu một cách toàn diện. Thông qua đó người dùng có thể đưa ra các nhận định ban đầu về thuộc tính, mô hình và mối quan hệ giữa các biến.
Data Pipeline đảm nhận vai trò quan trọng trong việc chuẩn bị dữ liệu trước khi thực hiện EDA. Dữ liệu thông thường đến từ nhiều nguồn khác nhau và có thể chứa lỗi, thiếu sót hoặc không đồng nhất. Data Pipeline giúp tiêu chuẩn hóa, làm sạch và chuẩn bị dữ liệu trước khi nó được sử dụng cho EDA.
Machine Learning

Máy học – Machine Learning
Ứng dụng trong Machine Learning của Data Pipeline là gì? Dưới đây là một số ứng dụng của Data Pipeline trong Machine Learning:
- Chuẩn bị dữ liệu: Để xây dựng và huấn luyện ML models, dữ liệu cần được xử lý và chuẩn bị. Data Pipeline giúp thực hiện các bước chuẩn hóa, xử lý giá trị thiếu, chọn lọc đặc trưng và phân chia dữ liệu huấn luyện và kiểm tra.
- Feature Engineering: Trong Machine Learning, việc tạo ra các đặc trưng (features) phù hợp là một bước quan trọng. Data Pipeline có thể hỗ trợ việc tạo ra, biến đổi và rút trích các đặc trưng từ dữ liệu gốc để đưa vào models.
- Tinh chỉnh và lựa chọn mô hình: Data Pipeline có thể được sử dụng để tạo ra các phiên bản mô hình khác nhau và thực hiện quá trình tinh chỉnh mô hình. Với Data Pipeline, người dùng có thể tự động huấn luyện và kiểm tra một loạt các mô hình với các tham số khác nhau.
- Đưa ra dự đoán: Sau khi xây dựng và tinh chỉnh mô hình, Data Pipeline được sử dụng để chuyển đổi và xử lý dữ liệu đầu vào mới để áp dụng mô hình đã được huấn luyện và đưa ra dự đoán. Các Data Pipeline có thể cung cấp việc chuẩn hóa và biến đổi dữ liệu đầu vào để phù hợp với dạng và định dạng dữ liệu mà mô hình yêu cầu.
Tìm hiểu thêm: Giới Thiệu Machine Learning Trên Power BI Service
Sự khác biệt giữa ETL và Data Pipeline
Sự khác nhau giữa ETL và Data Pipeline là gì? Data Pipeline và ETL (Extract, Transform, Load) là hai khái niệm quan trọng trong việc xử lý dữ liệu, nhưng có một số điểm khác biệt quan trọng:
| Data Pipeline | ETL (Extract, Transform, Load) | |
| Mục tiêu chính | Xử lý dữ liệu trong quá trình thực hiện tác vụ | Di chuyển dữ liệu từ nguồn ban đầu (Extract), sau đó biến đổi (Transform) và cuối cùng tải dữ liệu vào nơi đích (Load) |
| Phạm vi xử lý | Bao gồm cả quá trình chuẩn bị dữ liệu, trực quan hóa dữ liệu, và xử lý quá trình phân tích dữ liệu | Tập trung xử lý dữ liệu từ nguồn tới nơi đích |
| Tần suất cập nhật | Được triển khai theo nhiều cách khác nhau từ thực hiện một lần duy nhất cho một tác vụ cụ thể tới việc chạy tự động định kỳ. | Thường được thực hiện theo chế độ định kỳ hoặc lên lịch |
Bài viết trên đã cung cấp các thông tin cơ bản về Data Pipeline là gì và những thông tin quan trọng về Data Pipeline đến bạn. Hy vọng qua những thông tin trên bạn có thể sử dụng Data Pipeline phù hợp với dữ liệu doanh nghiệp của mình. Hãy liên hệ với Mastering Data Analytics – MDA qua Zalo 0961 48 66 48 để được tư vấn chi tiết về Lớp học Data Analyst để nâng cao trình độ phân tích trong các hoạt động BI của doanh nghiệp nhé!
Chia sẻ bài viết
Blog mới nhất





Bài viết liên quan

Knowledge
Data Encryption là gì? Lợi ích mà mã hóa dữ liệu mang lại

Knowledge
DBMS là gì? Chức năng của Hệ quản trị cơ sở dữ liệu

Knowledge
Data Dictionary là gì? Tại sao cần sử dụng Từ điển dữ liệu?

Knowledge
OLTP và OLAP khác nhau ở điểm nào? Có nên kết hợp cả 2 để tối ưu?

Knowledge
Vòng đời dữ liệu – Data Life Cycle là gì? Tầm quan trọng của vòng đời dữ liệu

Knowledge
Tích hợp dữ liệu – Data Integration là gì? Lợi ích của tích hợp dữ liệu

Knowledge
Database Server là gì? Những thông tin cần biết về Máy chủ cơ sở dữ liệu

Knowledge
SQL và NOSQL có gì khác nhau? Nên dùng loại cơ sở dữ liệu nào?

Knowledge
Roadmap là gì? Vai trò của Roadmap trong phân tích kinh doanh

Knowledge