Nâng trình phân tích dữ liệu kinh doanh bằng những khóa học của MDA

Tiếp theo bài trước, “Giới thiệu khái quát Visual Analytics cực hấp dẫn”. Hôm nay, chúng ta sẽ cùng tìm hiểu về Quy trình của Visual Analytics sẽ như thế nào?
Trọng tâm chính của visual analytics là thu thập và xử lý thông tin chi tiết về các tập dữ liệu lớn và phức tạp. Mô hình quy trình phân tích trực quan là một khái niệm quan trọng tích hợp các phương pháp phân tích và cả sự tương tác giữa con người với nhau.
Dưới đây là quy trình làm việc của mô hình Visual Analytics:

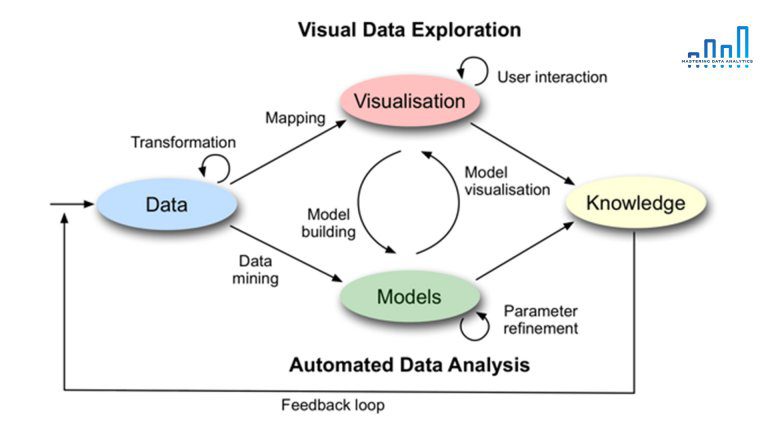
1. Data Transformation (Chuyển đổi dữ liệu)
Giai đoạn này còn được gọi là bin-counting (một trong những phương pháp encoding hữu ích). Chuyển đổi dữ liệu là quá trình trích xuất, sàng lọc, sửa đổi, tính toán và xử lý dữ liệu thô thành các dữ liệu sẵn sàng cho hoạt động phân tích. Dữ liệu thô thường không nhất quán, không chính xác và trùng lặp. Vì vậy, việc chuyển đổi dữ liệu là một bước quan trọng không thể thiếu để tạo báo cáo và ra insight có giá trị.
Đầu tiên, các nhà phân tích bắt đầu tìm hiểu để có được cái nhìn tổng quan nhất. Bao gồm đánh giá và thăm dò các khu vực thiết yếu có số lượng đóng góp cao nhất. Cụ thể sau đó, nhà phân tích bắt đầu lập bản đồ dữ liệu. Bước này để xác định được mối quan hệ giữa các bảng dữ liệu và loại biến đổi dữ liệu nào cần thực hiện.
2. Data Mapping (Lập sơ đồ dữ liệu)
Còn được gọi là trực quan hóa bản đồ nhiệt. Đây là quá trình tích hợp dữ liệu từ nhiều nguồn khác nhau. Data mapping giúp tạo kho dữ liệu (data warehouses) một cách dễ dàng, đảm bảo dữ liệu chất lượng và chính xác. Trong ứng dụng, có một mã màu được ánh xạ trên giá trị của mỗi ô vào bản đồ, ví dụ thông qua việc sử dụng thang độ màu sắc giúp người xem nhận thấy khu vực quan trọng cần tập trung.
3. Interaction (Mối tương quan)
Các đóng góp có khả năng liên quan đến nhau trong cùng một vùng không gian. Tốt hơn là nên xử lý chúng cùng nhau mặc dù nó có thể gây tranh cãi. Mặt khác, các khu vực tiềm năng là nơi tốt nhất để bắt đầu từ quá trình xử lý vì đó là trọng tâm chính. Người lập kế hoạch sử dụng các kỹ thuật “zooming” và “panning” để khám phá cách biểu diễn bản đồ nhiệt trực quan nhằm tập trung sự chú ý vào các vùng khác. Với việc thu phóng mỗi ô có thể tiết lộ sự đóng góp riêng lẻ của vị trí nhất định.
4. Contribution selection
Khi người lập kế hoạch muốn xem tình hình thực tế, họ có thể xem bằng cách chọn một dữ liệu hữu ích (contribution). Hệ thống có thể thực hiện một quy trình xếp hạng dựa trên mức quan trọng của dữ liệu theo mức độ gần về địa lý và có điểm tương quan với nhau.
5. Ranking (Xếp hạng)
Nội dung này còn được gọi là xây dựng mô hình. Tương tự như mô hình xếp hạng công cụ tìm kiếm, contribution được chọn hoạt động như một truy vấn để phát triển mô hình xếp hạng. Mục tiêu là sắp xếp tất cả các contribution được truy xuất theo sự tương đồng với nhau.
6. Model visualization (Hình ảnh hóa mô hình)
Nó còn được gọi là mã hóa điểm số. Xếp hạng cần được trực quan hóa để có thể kiểm tra mô hình xếp hạng. Sau đó, ánh xạ màu cho từng điểm contribution đã lưu trữ để thực hiện trực quan hóa bản đồ. Tuy nhiên, cũng giống như các công cụ tìm kiếm trên internet, thứ tự xếp hạng cũng có thể được hình dung dưới dạng danh sách giảm dần.
7. Knowledge processing
Bước cuối cùng của quy trình của Visual Analytics là Knowledge processing. Bước này được thiết lập trên mô hình xếp hạng trực quan trong việc triển khai phần mềm cụ thể. Trong đó việc tổng hợp contribution là một bước quan trọng hơn hết. Việc quản lý data và object cũng quan trọng không kém trong giai đoạn này.
Tóm lại, một bản tóm tắt thông tin từ phân tích trực quan giúp bạn xác định mô hình và xu hướng dễ dàng . Hiệu quả hơn so với việc xem bảng tính và hàng trăm, hàng triệu cột/hàng khác nhau. Biểu đồ và đồ thị sẽ giúp truyền đạt insight từ dữ liệu dễ dàng hơn.
Với mọi thắc mắc về các dịch vụ của chúng tôi, vui lòng inbox Fanpage Mastering Data Analytics. Để được tư vấn và giải đáp thắc mắc trực tiếp hãy gọi hotline 0899 093 368. Truy cập ngay Khóa học Business Intelligence để nhận thông tin khóa học mới nhất.