Nâng trình phân tích dữ liệu kinh doanh bằng những khóa học của MDA

Nhiều người vẫn nghĩ công việc Data Analyst chỉ đơn giản là “ngồi máy tính, kéo thả vài biểu đồ”. Hãy cùng khám phá sự thật về nghề nghiệp đầy thách thức này.
1. Thử Thách Trong Xử Lý Dữ Liệu
Thực tế hàng ngày:
- Đối mặt với dữ liệu thô, chưa được chuẩn hóa
- Xử lý nhiều nguồn dữ liệu khác nhau
- Giải quyết các vấn đề về chất lượng dữ liệu
Kỹ năng cần có:
- Thành thạo công cụ làm sạch dữ liệu
- Khả năng phát hiện và xử lý ngoại lệ
- Tư duy logic và cẩn thận
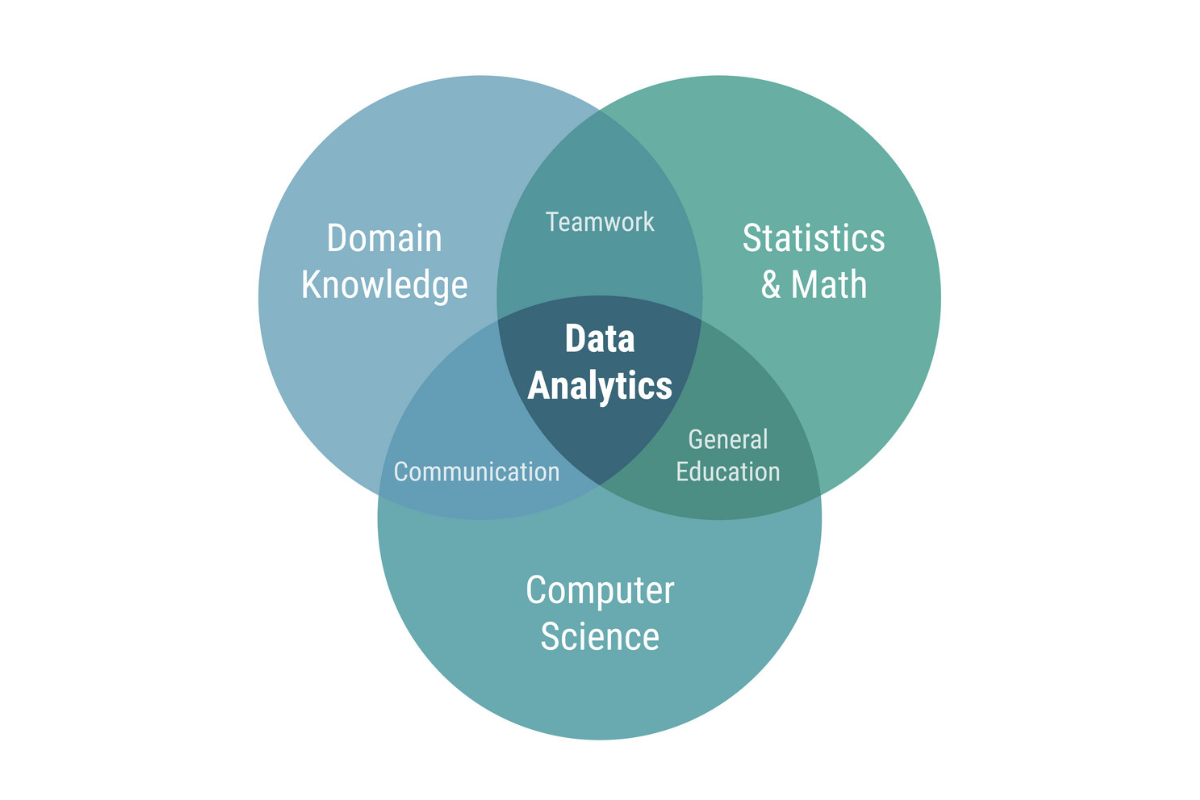
2. Vai Trò Trong Kinh Doanh
Trách nhiệm chính:
- Hiểu sâu về mục tiêu kinh doanh
- Xác định KPIs quan trọng
- Đề xuất giải pháp dựa trên dữ liệu
Yêu cầu chuyên môn:
- Kiến thức về ngành
- Khả năng phân tích định tính
- Kỹ năng tư vấn và đề xuất
Nguồn: Vector Stock
3. Quản Lý Kỳ Vọng Đa Chiều
Thách thức hàng ngày:
- Đáp ứng nhiều yêu cầu khác nhau
- Cân bằng thời gian và chất lượng
- Điều chỉnh phân tích theo từng đối tượng
Giải pháp:
- Thiết lập quy trình làm việc hiệu quả
- Ưu tiên hóa công việc
- Giao tiếp rõ ràng với các bên
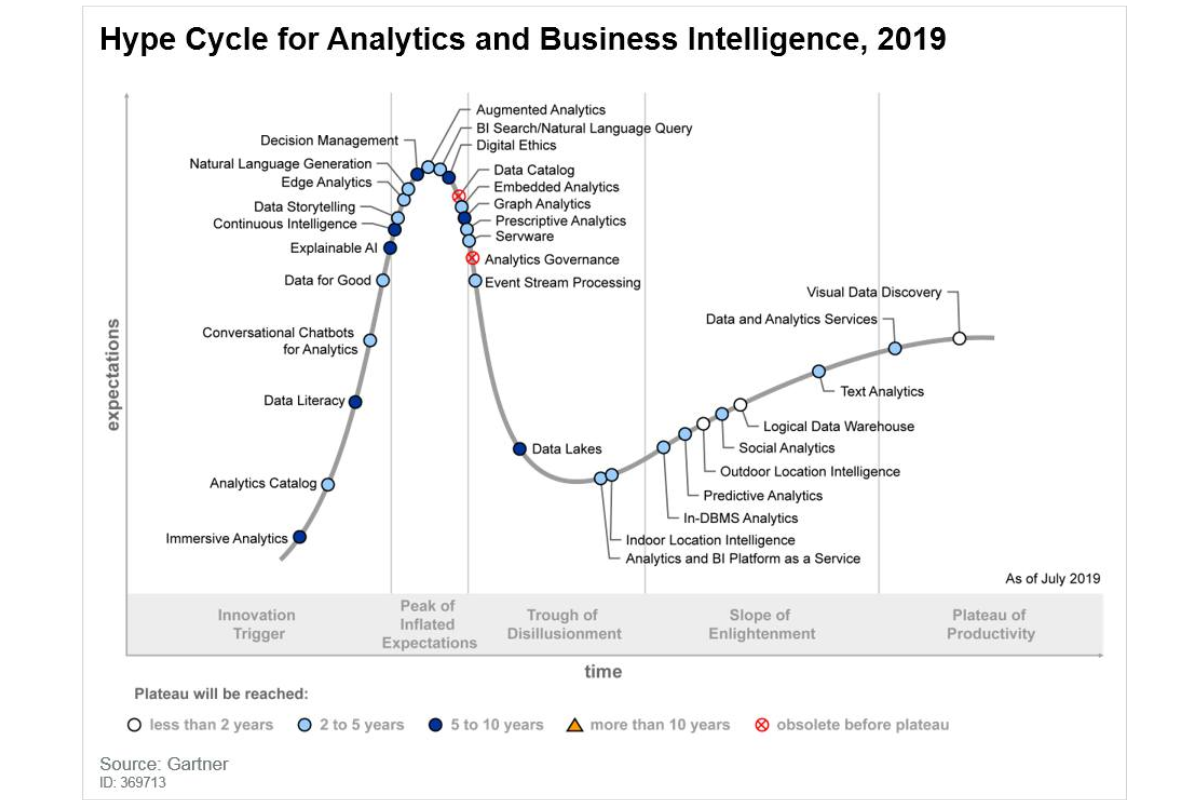
4. Phát Triển Chuyên Môn Liên Tục
Yêu cầu học tập:
- Cập nhật công nghệ mới
- Nâng cao kỹ năng phân tích
- Học hỏi từ cộng đồng chuyên môn
Lĩnh vực cần phát triển:
- Công cụ phân tích mới
- Kỹ thuật trực quan hóa
- Machine learning và AI
Nguồn: Gartner
5. Lời Khuyên Cho Người Mới
a) Chuẩn bị tâm lý:
- Sẵn sàng học hỏi liên tục
- Chấp nhận thách thức
- Kiên nhẫn trong quá trình phát triển
b) Đầu tư vào kỹ năng:
- Nền tảng thống kê vững chắc
- Khả năng kể chuyện bằng dữ liệu
c) Xây dựng portfolio:
- Thực hành với dự án thực tế
- Tham gia cộng đồng
- Chia sẻ kinh nghiệm
6. Kết luận
Đây không phải là vị trí “nhàn” như lời đồn, mà là một nghề nghiệp đầy thử thách nhưng cũng rất đáng để theo đuổi. Bạn đã sẵn sàng đối mặt với những thử thách này chưa?
Liên hệ MDA ngay và trang bị đủ “kiến thức, kinh nghiệm, và trải nghiệm” để gia nhập ngành phân tích dữ liệu với khóa học Business Intelligence tại đây hoặc liên hệ Zalo 0961 48 66 48 để được tư vấn chi tiết!
Tham khảo mạng lưới kênh tin tức về phân tích dữ liệu của Mastering Data Analytics tại đây