Nâng trình phân tích dữ liệu kinh doanh bằng những khóa học của MDA

Blog & Event
Các Cách Xử Lý Vấn Đề Imbalance Dataset?
Mục Lục
Khi phân tích dữ liệu, một trong những vấn đề lớn nhất phát sinh khi thực thi nó là sự hiện diện của một tập dữ liệu không cân bằng (Imbalance Dataset). Do đó, suy luận từ các mô hình trở nên mất cân bằng và không chính xác khi các lớp được phân phối không đồng đều. Trong bài viết này sẽ giới thiệu một số kỹ thuật để giải quyết vấn đề này.
1. Đo lường chỉ số (Evaluation Metrics) trong Imbalance Dataset
Chúng ta có thể sử dụng các số liệu sau để đánh giá mô hình với dữ liệu không cân bằng:
- Recall/Sensitivity : Đối với một lớp, có bao nhiêu mẫu được dự đoán chính xác.
- Precision/Specificity : Cho phép tính toán một vấn đề cụ thể của lớp.
- Điểm F1 : Mức độ thu hồi trung bình và độ chính xác hài hòa.
- MCC : Tính toán hệ số tương quan giữa các phân loại nhị phân được dự đoán và quan sát được.
- AUC–ROC : Không phụ thuộc vào những thay đổi về tỷ lệ người trả lời, nó suy ra mối quan hệ giữa tỷ lệ dương tính giả và tỷ lệ dương tính thật.
2. Lấy lại mẫu (Resampling)Lấy lại mẫu (Resampling)
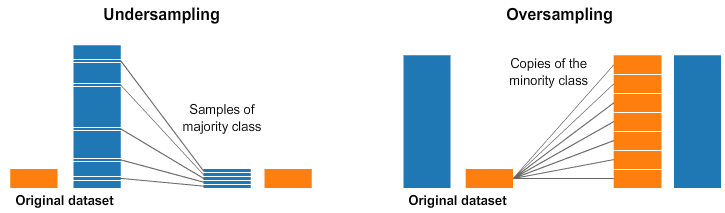
Oversampling được thực hiện khi số lượng dữ liệu không đủ. Trong quá trình này, chúng tôi tăng kích thước của các mẫu hiếm để cân bằng tập dữ liệu. Các mẫu được tạo bằng các kỹ thuật như SMOTE, bootstrapping, và lập lại mẫu. Kỹ thuật phổ biến nhất là ‘Lấy mẫu ngẫu nhiên’. Các bản sao ngẫu nhiên được thêm vào lớp thiểu số để cân bằng với lớp đa số. Tuy nhiên, điều này có thể gây ra tình trạng overfitting.
Mặt khác, Undersampling được sử dụng để giảm kích thước của lớp phong phú. Do đó, các mẫu hiếm được giữ nguyên và kích thước được cân bằng bằng cách chọn một số lượng mẫu bằng nhau từ lớp phong phú để tạo tập dữ liệu mới cho việc lập mô hình tiếp theo. Tuy nhiên, điều này có thể khiến thông tin quan trọng bị xóa khỏi tập dữ liệu.
3. Kỹ thuật lấy mẫu quá mức thiểu số tổng hợp (SMOTE)
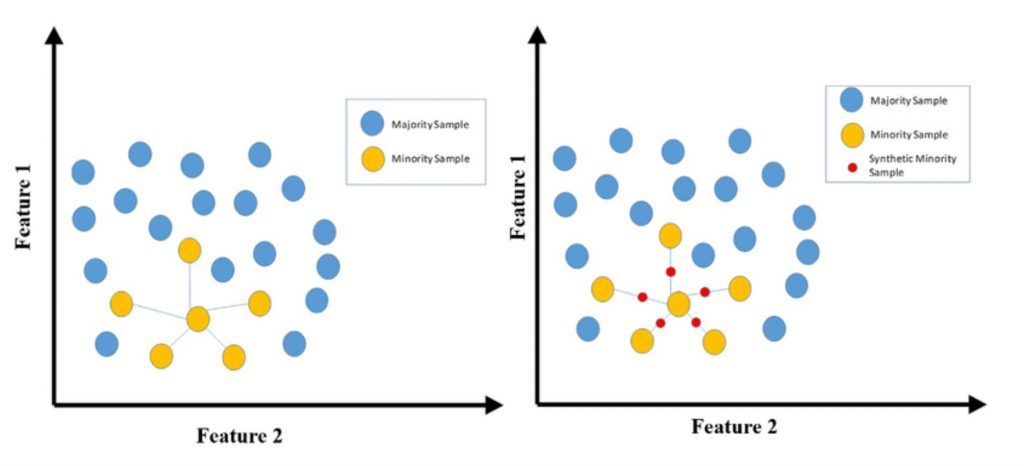
Kỹ thuật lấy mẫu quá mức thiểu số tổng hợp để xử lý vấn đề Imbalance Dataset
Một giải pháp thay thế tốt để xử lý các vấn đề về Oversampling và Undersampling là SMOTE, trong đó một điểm ngẫu nhiên được chọn từ lớp thiểu số và K-nearest neighbour được tính toán, tiếp theo là cộng các điểm ngẫu nhiên xung quanh điểm đã chọn. Các điểm liên quan được thêm vào mà không làm thay đổi độ chính xác của mô hình.
Xem thêm: Tạo Hình Ảnh Power BI Bằng Cách Sử Dụng Python
4. Xác thực chéo K-fold (K-fold Cross Validation)
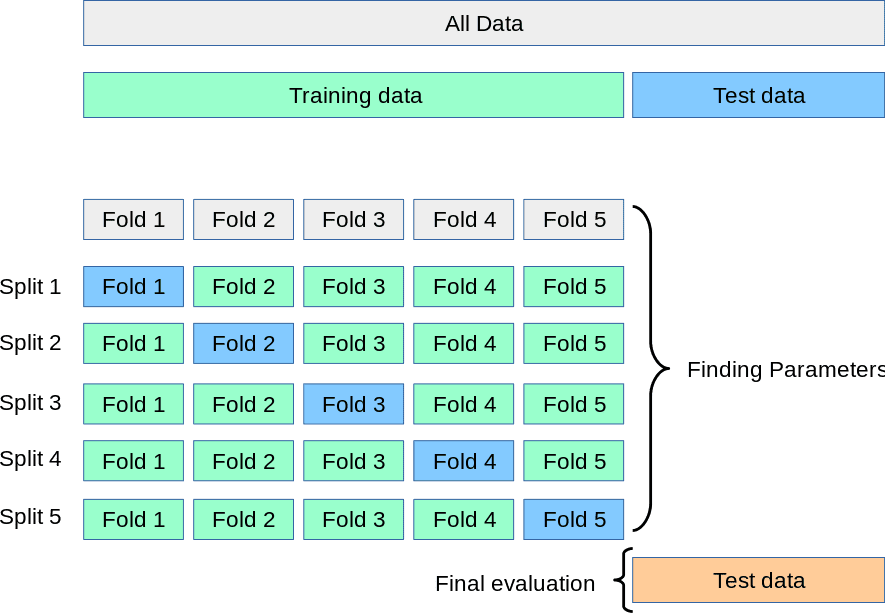
Kỹ thuật này liên quan đến việc xác thực chéo tập dữ liệu sau khi nó được tạo bởi quá trình lấy mẫu quá mức vì nó giúp dự đoán lớp thiểu số dễ dàng hơn.
Quy trình hoàn hảo để xác thực chéo K-fold trong bộ dữ liệu không đầy đủ là:
- Loại trừ một số lượng dữ liệu để xác thực sẽ không được sử dụng để lấy mẫu quá mức, lựa chọn tính năng và xây dựng mô hình;
- Theo dõi bằng cách lấy mẫu quá mức lớp thiểu số mà không có dữ liệu bị loại trừ trong tập huấn luyện;
- Tùy thuộc vào số lần gấp, tức là ‘K’—Lặp lại ‘K’ lần.
5. Tập hợp các bộ dữ liệu được lấy mẫu lại (Ensembling resampled datasets)
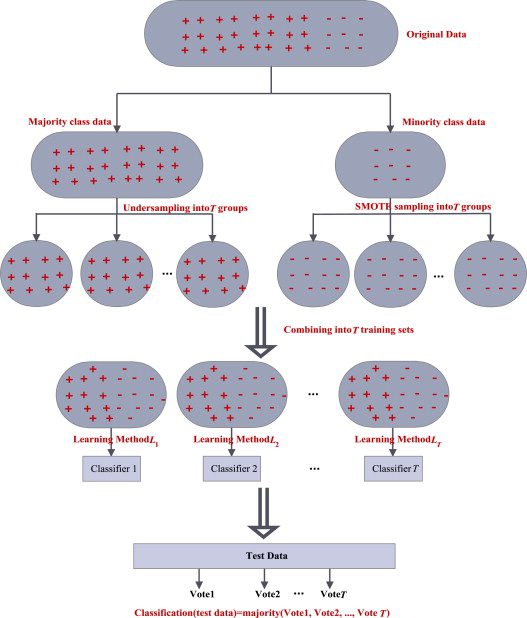
Cách rõ ràng nhất nhưng không toàn diện là sử dụng nhiều dữ liệu. Do đó, tập hợp các bộ dữ liệu được lấy mẫu lại khác nhau là một kỹ thuật khác có thể khắc phục các sự cố trong khi khái quát hóa bằng cách sử dụng rừng ngẫu nhiên hoặc hồi quy logistic.
Một trong những cách phổ biến là sử dụng ‘BaggingClassifier’ để lắp ráp. Trong phương pháp này, tập dữ liệu được lấy mẫu quá mức hoặc chưa được lấy mẫu được kết hợp để đào tạo bằng cách sử dụng cả lớp thiểu số và lớp phong phú trong tập dữ liệu.
6. Vài kỹ thuật khác
- Chọn đúng mô hình
- Thu thập thêm dữ liệu
- Phát hiện bất thường
- Lấy mẫu lại bằng các tỷ lệ khác nhau
Bài viết trên đã nêu ra một số kỹ thuật để giúp bạn có thể giải quyết được vấn đề Imbalance Dataset của bạn. Tuy nhiên hãy nhớ rằng, kỹ thuật nào cũng sẽ có ưu điểm và nhược điểm vì thế bạn cần phải tìm hiểu kỹ chúng trước khi quyết định dùng kỹ thuật nào để đem lại kết quả tốt nhất.
Xem thông tin khai giảng Khóa học Business Intelligence mới nhất tại Mastering Data Analytics. Liên hệ 0961 48 48 66 hoặc inbox Fanpage Mastering Data Analytics để đăng ký nhanh nhất nhé!
Chia sẻ bài viết
Blog mới nhất
Bài viết liên quan

Blog & Event
Top 5 Tài Liệu Học Data Analysis (KPI) Hữu Ích Cho Người Mới Bắt Đầu

Blog & Event
4 Kiểu Phân Tích Tưởng Đúng Mà Sai ‘Kinh Điển’ Khi Làm Dashboard

Blog & Event
Actionable Insight – Kim chỉ nam cho quyết định hay chiếc mặt nạ định kiến

Blog & Event
5 video YouTube tiếng Anh chất lượng giúp bạn tự học Power BI

Blog & Event
5 Website Luyện Kỹ Năng Trực Quan Hóa Dữ Liệu Không Thể Bỏ Qua

Blog & Event
Tư Duy Phân Tích Dữ Liệu: 5 Cách Rèn Luyện Hiệu Quả

Blog & Event
Ra Quyết Định Dựa Trên Dữ Liệu: Cần Tốc Độ Hay Độ Chính Xác?

Blog & Event
AI Phân Tích Dữ Liệu: 5 Rủi Ro Doanh Nghiệp Cần Lưu Ý

Blog & Event
5 Newsletter Phân Tích Dữ Liệu Miễn Phí Chất Lượng Cao

Blog & Event